太长不看
kun的高性能和TDengine密不可分kun为电池厂降本增效
理论对比1
| 使用前 | 使用后 |
|---|---|
 |  |
| 海量的分容设备 | 原10%的分容设备 |
| 分容充放电过程耗电量巨大 | 原10%的能耗 |
| 满载产能固定,出货慢 | kun可通过横向扩展服务器集群线性叠加性能2,快速出货 |
| 设备耗资巨大 | 原10%的设备预算 |
| 车间占地面积大、楼层高,需要大量堆垛机等 | 原10%的空间占用 |
实际案例
| 原设计 | 引入容量预测后 | |
|---|---|---|
| 分容库位规模 | 300 分容库位 ¥5400 万 |
30 分容库位 ¥540 万 |
| 分容库位耗电量 | 7,900,000 度/年 ¥790 万/年 |
79,000 度/年 ¥7.9 万/年 |
| 工艺总耗时 (库位数*工艺时间*每天次数) |
6,000 小时/天 | 60小时/天 |
| 总计 | 总设备投资减少 ¥4,860万 每年能耗投入减少 ¥710万/年 |
|

项目为2022年11月上线,目前已经正常生产近两年,前期调试和工艺磨合周期为2个月。
经过前期两个月的共同努力,产线落实了工艺和制程一致性的规范,确保容量预测介入的生产整体在较稳定的环境下进行,降低了NG率的同时提高了预测精度。
每天容量预测系统为产线完成(保密,嘻嘻)只电芯的容量预测结果。其平均误差保持在0.37%,预测判别NG率为5.7%。
目前容量预测系统完全达到客户要求,成功为客户节约了超过5000万的经济价值,并完成了全局验收。
关于kun的介绍,请参见项目首页。
初识TDengine
我们和TDengine的缘分要从2021年底开始。
彼时我们的系统(kun)已经基本完成,后端数据库使用了MariaDB作为数据持久化的方案。但当我用大量的模拟数据进行交付测试时,遭遇了一个性能瓶颈问题:按时间查询太慢了。
尽管我们系统的主要功能是利用机器学习等算法提供服务,但车间现场电芯的生产数据(生产时间、条码、经转的设备号和通道号等)均需要记录在案。
这些“流水账”有什么用呢?
我们的甲方(电池厂)要对客户(比如电动轿车厂)负责,质量上肯定是要精益求精的。因此,如果某些电芯预测出的容量偏离了正常分布3,就需要及时回溯上述数据以便于快速定位产线上的问题,进而及时纠错,恢复电芯容量的精度。
举个栗子,某化成设备在某个位点上的夹具温度传感器出了故障,测量的温度不准确,这里涉及到几个问题:
- 哪个设备上的夹具温度偏离了正常分布?
- 具体是该设备上的哪个充放电位点?
- 该位点是从什么时间开始出现故障的?
为保障生产,当故障出现时,工厂都是希望第一时间定位和解决问题的。一般的做法是,快速查询出可能出现问题的时段的数据,再进行分析。
如果使用MariaDB,当单表数据量达到一定规模时,查询性能会急剧下降,对于难以索引的时间字段更加如此。如果一定要继续使用MariaDB作为数据持久化的方案,则需要在写入时就在应用层代码中建立复杂的分片分区逻辑,以便于未来在查询时快速定位到具体的数据。
更进一步地,我们也希望数据库有强大的对新写入数据的即时计算的能力,这样就可以及时上报错误,要比人为发现问题后再去反查更为安全便捷。
带着需求,我开始重新考虑数据库选型的问题。在社区搜索时,偶然间发现TDengine这个产品,带着好奇心看完了它的主要特性,发现TDengine与kun简直就是天作之合:
| TDengine的特性 | 我们的需求 | 举例 |
|---|---|---|
| 数据模型方面:一个采集点一张表 | 一种工艺对应一个批次,每个批次一张表 | 一个批次就相当于一个采集点 |
| 通过超级表实现采集点之间的聚合操作 | 跨批次统计 | 前文的例子中,如果多个批次同时使用了该故障设备,需要跨批次统计夹具温度的分布情况 |
| 流式计算 | 及时发现生产异常并预警 | 可通过在流式计算中应用窗口聚合实时获取字段异常值 |
可以看到,TDengine的特性与我们的需求可谓是严丝合缝。而且我相信,它解决了许多工业场景的痛点,在这一领域的许多开发者深入了解它之后,都会有“相见恨晚”的感觉。
对复杂的矢量数据库说不!
为了保障预测容量的精度,kun采用了持续机器学习(continuous machine learning)的设计:
| 传统方案 | kun的方案 |
|---|---|
 |  |
| 全系统部署单个模型 不断地 获取新数据 重新训练模型 重新部署到现场 …… | 对每个批次分别处理 持续收集数据 周期性训练模型用于预测 模型权重滚动更新 |
通过这种机制,kun得以以全自动的方式始终保持模型的行为和最近期的生产状况保持一致。
但这样的设计也面对两个挑战:
- 功能方面:某批次刚建立时,训练数据集的规模非常小,该如何保障容量预测的精度和效率?
- 性能方面:某批次生产很长一段时间后,训练数据集的规模非常大,该如何高效查询用于模型训练和推理?
训练集规模非常小
为了节约设备和空间成本,厂家决定选用kun之后往往只会采购原生产所需的分容设备的10%~30%。
这样小规模的分容设备产生的可用于模型训练的全流程数据非常少。
另一方面,电芯的下游用户给电池厂的订单总有截止日期,此时由于分容设备不足,产能表面上也大大降低了。
kun通过我们自研的曲线搜索算法很好解决了这一难题:经过过滤的全流程数据被收进数据库,当有新电芯待预测容量时,通过曲线搜索算法从中检索出相似的曲线,进而归纳得到预测容量。
相信熟悉矢量数据库(vector database)产品的工程师都会感到非常熟悉:这不是矢量数据库的常见功能吗?!
矢量数据库往往原生支持一些基于聚类(比如根据距离)的搜索算法,常见的有k-NN (k-nearest Neighbor)、HNSW (Hierarchical Navigable Small World)或者IVF (Inverted File Index)等。
但如果在我们的系统中额外集成一种矢量数据库,不仅运维成本提升了,也为程序员们引入了额外的心智负担。
TDengine提供的聚合函数、流式计算等特性,配合其灵活的自定义函数(User-defined Function, UDF),使得我们可以在写入全流程数据的同时就高效地进行一系列复杂的预处理,为快速搜索近似曲线提供了可能。
使用矢量数据库还有一个不便之处,就是电芯复杂的元数据(metadata)无法直接与计算用的特征值(features)建立绑定关系。在调研选型阶段,我们就留意到,除了上文提到的优秀特性,TDengine还提供了标准的SQL语法,也有和关系型数据库相似的关联查询用法,使程序员可以以很小的学习代价来记录和利用字段间的关联性,开发更简单;TDengine的Rust连接器还提供了参数绑定这种更高效的写入方式,当客户端有数据发送过来时,我们可以处理后快速写入;后续如果用户需要将计算结果与元数据结合在一起分析(详见生产异常预警小节),一次查询就可以获取所需的全部信息,这样的数据建模极大地提升了运行时效率。
可以看出,TDengine在一整条数据链路的各个环节都为开发者提供了相当大的便利。
训练集规模非常大
熟悉深度学习的朋友们都知道,为了使模型的参数得到尽量利用以提高其泛化性,理应在每个epoch中将整个数据集按批次(batch)喂给模型学习。
上文提到,经过预处理的features也通过TDengine持久化。但数据量达到一定规模后,简单地将整个数据集从数据库中一次取出用于训练是不可取的,会有严重的性能问题甚至引起OOM(Out Of Memory,内存不足)中断。
由于要将当前batch的数据实时从数据库取出加入训练,直观上可能操作起来会有一些技术问题。
所幸,TDengine的开发团队对社区的支持非常友好。kun是完全基于Rust语言开发的,我们早期在调研时就注意到,TDengine也为Rust实现了连接器,其中有两个亮点:
- 同时支持同步/异步上下文
- 借由FFI(Foreign Function Interface,外部语言接口)实现了Rust与C语言的primitive数据类型的无缝对接
一般来讲,由于网络传输及数据查询均需要一定的时间,因此建议在异步上下文中与数据库进行交互。但考虑到训练模型是CPU密集型的计算任务,我们将其置于rayon开启的线程池中运行。此时如果有数据需要与数据库交互,理论上可以通过消息通道机制将消息传出实时写入数据库,但也有些场景不要求并发(比如一次性地查询某些数据),此时连接器支持同步上下文就显得尤为方便。
而FFI方面则是良好的性能保障。比如我们利用Intel的原生SIMD指令集对计算进行了加速,通过实现serde::Deserialize可以直接把查询出的features转为所需的数据类型,避免了不必要的内存分配:
#[derive(Clone, Debug)]
pub struct ReferenceFeatures {
features: __m512i,
capacity: f32,
}
impl<'de> Deserialize<'de> for ReferenceFeatures {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: Deserializer<'de>,
{
struct ReferenceFeaturesVisitor;
impl<'de> Visitor<'de> for ReferenceFeaturesVisitor {
type Value = ReferenceFeatures;
fn expecting(&self, formatter: &mut fmt::Formatter) -> fmt::Result {
formatter.write_str("struct ReferenceFeatures")
}
fn visit_map<V>(self, mut map: V) -> Result<ReferenceFeatures, V::Error>
where
V: MapAccess<'de>,
{
let mut arr: [MaybeUninit<i16>; 32] =
unsafe { MaybeUninit::uninit().assume_init() };
let mut index = 0;
let capacity = loop {
if (map.next_key::<String>()?).is_some() {
if index < 32 {
arr[index] = MaybeUninit::new(map.next_value()?);
index += 1;
} else {
break map.next_value()?;
}
};
};
let features =
unsafe { _mm512_loadu_epi16(transmute_copy::<_, [i16; 32]>(&arr).as_ptr()) };
Ok(ReferenceFeatures { features, capacity })
}
}
deserializer.deserialize_struct("ReferenceFeatures", &[""], ReferenceFeaturesVisitor)
}
}
高效的数据可视化
电芯分档的“金标准”是容量值。因此,生产监督人员往往非常关注预测得到的容量值的分布。随着产量的累积,单个批次可能在一段时间内生产的电芯数目非常多,如果按照传统做法从数据库查出全部的数据,再在应用层汇总计算,如此大量的数据传输会使前端经历相当久的延迟才能绘制出统计图表,破坏了用户体验。
好消息是,通过TDengine的窗口切分查询和聚合函数可以很方便实现这种直方图汇总,在数据库层直接完成计算后返回结果:
let capacity_histogram_data: Vec<CapacityIntervalHistogram> = taos
.query(format!(
"SELECT histogram(capacity,'linear_bin','{}',0) as capacity_rang
FROM inference.`{}` WHERE ts > (NOW - {}d) ;",
serde_json::json!({
"start": min_capacity as i32,
"width": (max_capacity as i32 / total_capacity_intervals),
"count": total_capacity_intervals,
"infinity": false
}),
table_name,
ts_n_days
))
.await?
.deserialize()
.try_collect()
.await?;
在前端就可以直接利用返回值绘图了:
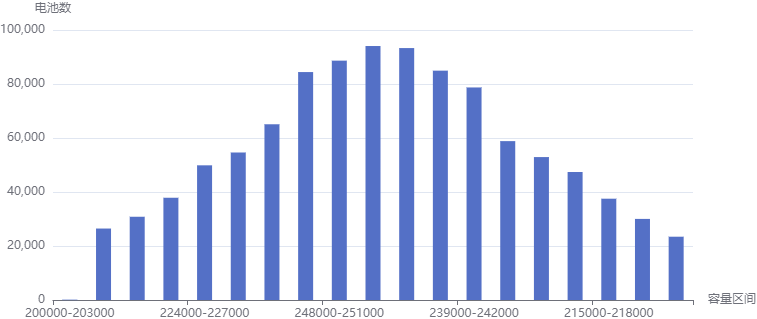
生产异常预警
现代电池厂多采用全自动产线,但受制于设备和软件等因素,产线往往缺乏即时的反馈能力。因此,为了保障出货速度和质量,厂家的生产监督人员(比如工艺员和技术员等)有一项重要而繁琐的工作:以一定间隔(比如4~6小时)收集数据并制作报表分析,以便及时发现异常数据,再定位到异常的工序甚至设备,进而纠错或修理。
这样的工作方式主要有两个弊端:
- 间隔太久,生产异常难以第一时间被发现和处理
- 工作内容重复、工作量太大
那么有没有一种全自动的方式来纠错和预警呢?当然我们可以部署一个计划任务,每隔一段时间就查询所有的关键数据(比如上柜电压、某时刻的夹具温度等)的数值特征(比如均值相对于总体的偏离程度等),再在应用层进行分析。同样地,这种做法有和上文类似的问题,数据库发送回查询结果时大量的数据传输和应用层做计算时的高CPU负载可能使生产环境苦不堪言。这样的性能开销也意味着这类型的任务无法经常执行。
德国著名的机械工程学家Klaus Martin Schwab在2016年提出了工业4.0的概念4,也被称作第四次工业革命,其中一部分目标是建立具有自适应性的智能制造工厂。为向这一惊艳的概念致敬,我们计划在下个版本中通过TDengine的流式计算特性来实时对上述关键数据进行分析。由于这些数值特征在数据写入的时候就已经以极小的代价计算完毕,需要汇总时按需查询、呈现结果就变得异常容易和高效。这样的做法将计算的负载均匀分摊在程序运行的整个生命周期中,是极佳的“削峰填谷”思想的实践。
运行环境
作为一款时序数据库产品,TDengine对硬件的要求真的非常友好。得益于它优异的数据压缩比率,我们在生产环境的硬件配置一降再降:
- 三台机架式服务器:
配置 参数 系统 Ubuntu 24.04 处理器 Intel® Xeon® Silver 4314 硬盘 2T NVME SSD 内存 4 * 16GB - TDengine服务端版本: 3.2.3.0
- 高可用结构
3个 mnode- 每个数据库均设置
3个副本(replica 3)
TDengine,工业软件开发团队的乌托邦!
均以10%的电芯做全流程估算,详见首页的整体架构章节
仅代表分容部分,实际产能可能受到各个生产环节制约
如果只有系统误差,一般可以看做这类数据符合正态分布