问:支持(容量的)温度补偿吗?
答:严格来说,kun没有温度补偿的概念。
但请求预测时我们会要求指定一个理论分容温度,可以看做最终返回的容量是分容所得容量加上(或减去)计入该温度的贡献后补偿的部分容量所得的结果。
问:只用化成曲线数据会不会不靠谱?
答:我们在研发阶段进行了大量的实验和测试,证实了化成阶段的曲线数据中的信息是足以表征电池的理化性质,进而获得容量的。
实验也证明,提取特征的方式和神经网络的架构起到更大的作用。
当然,对于对这一设计缺乏信心的厂家,我们也支持其他混合了分容数据的使用模式。
尽管后者需要做一部分分容,但仍然可以节约相当的能源和时间,也对提升产能有帮助。
问:数据预处理的方式是怎样的?
答:数据清洗基于一个基本假设:存在电芯的某些物理量,其中每个物理量在总体中的分布都是符合正态分布的。
基于这一假设,我们可以通过某物理量的值是否位于正态分布的双尾部分决定是否剔除某电芯的数据。
这一清洗行为会导致NG:
- 如果发生在推送全流程数据阶段,则这部分NG数据不会出现在训练数据中
- 如果发生在预测阶段,则会直接报告该电芯NG
问:该如何选取少量做全流程的电芯?
答:很多程序员在调用ikun和我们的服务端对接时都有类似的疑惑:
如果只能以托盘为单位管理电池,且选取了
10%的电芯做全流程,难道我要等待10个托盘做完化成后再从中随机挑选1个去做完全流程?
那如果生产不够10个托盘时就停止了呢?
显然不是这样的,我们可以借助线性的伪随机数生成器来处理这个问题。
比如,规定一个[0, 1)的区间,每当有托盘完成时,都从中随机生成一个随机数:
- 若该值**<
0.1**,则将该托盘上的电芯全部送去做全流程 - 若该值**≥
0.1**,则将该托盘上的电芯通过容量预测获取容量值
以下是一些代码示例,有助于客户端用户理解这一逻辑:
// cargo add rand
use rand::Rng;
fn main() {
let mut rng = rand::thread_rng();
let mut train_vec: Vec<i32> = vec[];
let mut predict_vec: Vec<i32> = vec[];
let data: Vec<_> = (1..101).collect();
for &value in &data {
if lcg_value() < 0.1 {
train_vec.push(value);
} else {
predict_vec.push(value);
}
}
println!("{:?}", train_vec);
println!("{:?}", predict_vec);
}
import random
data = list(range(1, 101))
train_list = []
predict_list = []
for v in data:
if random.random() < 0.1:
train_list.append(v)
else:
predict_list.append(v)
print(train_list)
print(predict_list)
<?php
$data = range(1, 100);
array_map(function($v) use (&$train_array, &$predict_array) {
if (lcg_value() < 0.1) {
$train_array[] = $v;
} else {
$predict_array[] = $v;
}
}, $data);
var_dump($train_array);
var_dump($predict_array);
问:模型有预训练的权重吗?新加入的全流程数据对权重有何影响?
答:容量预测系统没有预训练的模型权重,为了尽量精确描述批次的特征,对于每个批次都会从头训练(train from scratch)新的模型。
当系统检查到有一定量的新的训练数据加入后,会将原来模型的某些层的权重解冻(unfreeze),用新数据对模型进行微调(fine-tuning)。
问:既然kun是人工智能应用,在某批次数据量尚少时,如何确保精度?
答:容量预测除了会通过深度学习模型进行推理外,我们还内置了一个效率非常高的曲线搜索算法。该算法会基于数据库内已有曲线间的距离进行搜索,并基于与待预测曲线最相近的一批曲线归纳出近似的容量。
如果搜索不到近似的曲线,或近似的曲线数目不够(提供不到有力的支持),该电芯会被判为NG(不可预测)。由于有可靠的依据,该算法的精度非常好。
问:化成批次、分容批次和容量预测的批次之间是什么关系?
答:容量预测的批次和其他工序的批次之间没有直接的对应关系。
方便起见,MES等系统也可以自行建立绑定关系,比如将化成批次_分容批次这样拼接后的字符串作为容量预测批次,以确保工艺的一致性并保留一定的区分度。
问:什么是不可预测(NG类型Unpredictable)?为什么看似很相近的两条曲线一条被成功预测出容量,另外一条不可预测?
太长不看:
这个有什么好解释的?国家规定身高 160 cm 以上可以参军,难道你非要拉着负责人问:我 159.5 cm 只差了0.5 cm,你凭什么把我刷掉?
详细解释:
为了控制最大误差,我们在模型中引入了一个判别机制,这个机制可以近似看做二分类的机器学习问题:
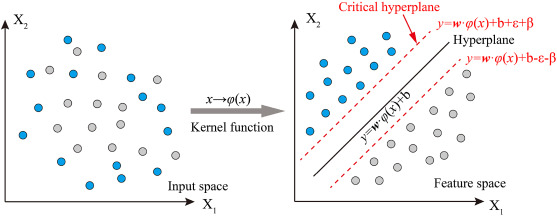
如图,在经过一系列在超空间中的变换后,样本(曲线代表的电芯)被超平面(Hyperplane,黑色实线)区分为可预测(蓝色)和不可预测(灰色)。 成功预测的那条曲线可能已经位于临界超平面(Critical hyperplane,红色虚线)与超平面之间了,在这样的临界情况下,与其相似的另一曲线有一定概率位于超平面的另一侧,即不可预测。